深入解读“寒武纪”后,我们对Google TPU有了这些认识
由于Google并没有公布TPU的设计,因此我们只能大概根据中科院目前的“寒武纪”神经网络芯片进行推断。
雷锋网按:本文作者龚黎明,威盛电子高级芯片工程师。由于提及“寒武纪”芯片,雷锋网特邀中国科学院计算技术研究所陈天石教授对本文做了修正把关,以呈现更加完整专业的内容,特此感谢。
在Google I/O 2016的主题演讲进入尾声时,Google提到了一项他们这段时间在AI和机器学习上取得的成果,一款叫做Tensor Processing Unit(张量处理单元)的处理器,简称TPU。

根据TPU团队主要负责人介绍,TPU专为Google机器学习应用TensorFlow打造,能够降低运算精度,在相同时间内处理更复杂、更强大的机器学习模型并将其更快地投入使用。Google数据中心早在一年前就开始使用TPU,其性能把摩尔定律往前推进到7年之后。之前打败李世乭的AlphaGo就是采用了TPU做了运算加速。
根据Google所言,TPU只在特定应用中作为辅助使用,公司将继续使用CPU和GPU。并且Google并没有对外销售TPU的打算。因此,TPU虽好,但仅限Google内部,而且即便使用TPU,也是用作辅助CPU和 GPU。
谷歌并没有公布TPU是怎么设计的,因此似乎很难对其一探究竟。不过,要知道谷歌的TPU并不是什么黑科技,只不过是正常的一款专用加速芯片。而且,这也不是世界上第一款用来做深度学习的专用芯片。IBM和我国中科院其实都有类似成果。
IBM 在2014年研发出脉冲神经网络芯片TrueNorth,走的是“类脑计算”路线。类脑计算的假设是,相似的结构可能会出现相似的功能,所以假如用神经电子元件制造与人脑神经网络相似的电子神经网络,是否可能实现人脑功能呢?这其实有点像人类研究飞行器的过程。我们都知道鸟会飞是因为有翅膀,人没有。所以假如给人也弄一对翅膀,人是不是也能飞?
早先人类其实有这么一个探索过程。如今人类要探索大脑,但是大脑何其复杂?IBM的这款芯片就是通过打造类脑的芯片架构,来期望得到大脑同样的功能,就算达不到,能模拟一下也很有意义。大意如此,当然实际上复杂多了。目前这款芯片理念很超前,还处于深入研究阶段,算得上是黑科技。
今天要重点讲的其实是中科院的这款“寒武纪”芯片。2016年3月,中国科学院计算技术研究所发布了全球首个能够“深度学习”的“神经网络”处理器芯片,名为“寒武纪”。该课题组负责人之一、中科院计算所陈天石博士透露,这项成果将于今年内正式投入产业化。在不久的未来,反欺诈的刷脸支付、图片搜索等都将更加可靠、易用。下图是“寒武纪”的芯片板卡。

之所以重点讲,是因为Google的TPU芯片并没有公开设计细节,连是谁代工的都没有公开。但是同样作为深度学习的芯片,有理由相信中科院的“寒武纪”与Google的TPU在设计理念上是相同的。在讲这个之前,先简单科普一下人工智能和深度学习。
1981年的诺贝尔医学奖,颁发给了David Hubel和Torsten Wiesel,以及Roger Sperry。前两位的主要贡献是,发现了人的视觉系统的信息处理是分级的。如下图所示:从原始信号摄入开始(瞳孔摄入像素),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定眼前物体的形状,比如是椭圆形的),然后进一步抽象(大脑进一步判定该物体是张人脸),最后识别眼前的这个人。
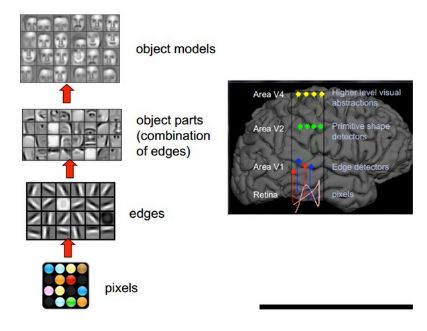
而深度学习(Deep Learning),恰恰就是模仿人脑的机制来解释数据。通过组合低层特征形成更加抽象的高层特征(或属性类别)。例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层次表达,例如边缘检测器、小波滤波器等,然后在这些低层次表达的基础上,通过线性或者非线性组合,来获得一个高层次的表达。此外,不仅图像存在这个规律,声音也是类似的。比如,研究人员从某个声音库中通过算法自动发现了20种基本的声音结构,其余的声音都可以由这20种基本结构来合成!
对于深度学习来说,其思想就是堆叠多个层,上一层的输出作为下一层的输入。深度神经网络由一个输入层,数个隐层,以及一个输出层构成。每层有若干个神经元,神经元之间有连接权重。每个神经元模拟人类的神经细胞,而结点之间的连接模拟神经细胞之间的连接。
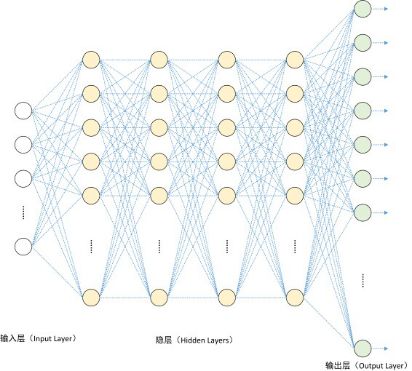
当然了,以上这些原理都不是重点。我们只需要明白深度神经网络模拟了大脑的神经网络,上图的每个圈圈都类似大脑的一个神经元。通过采用专用芯片进行神经元的运算加速,相比于采用CPU这种通用运算器,可以大大提高神经网络的性能。根据“寒武纪”芯片的介绍,它可以一条指令完成多个神经元的并行处理。据此推断,Google的TPU很有可能也是这么设计的,也就是说,支持一条指令完成神经元的多次计算。
“寒武纪”专用处理器还有配套的指令集,叫Cambricon。我们知道,指令集乃是一个处理器架构的核心。知道了一款处理器实现了哪些指令,其实也就知道了这款处理器适合做什么,也大概知道了这款处理器的硬件设计。
【雷锋网注:有读者认为寒武纪专用处理器配套的指令集叫DianNao,其实DianNao系列特指中科院计算所前期和国际合作者共同发表的学术论文提出的架构;而“寒武纪”特指寒武纪公司(中科院计算所的产业化公司)独立开发的商用芯片。寒武纪的正式英文名为“Cambricon”】
Cambricon指令集的特点是单指令可以做完一次向量或矩阵运算,因此假如我们知道了深度学习的具体算法,那么其实也就知道了每个神经元可以规约为何种向量或矩阵运算,其实也就推断出了Cambricon的指令集。以此类推,如果我们知道了Google的深度学习算法,假设也是每条指令实现多个神经元相关的向量或矩阵运算,那么其实也能推断出TPU的指令集。这种假设应该是很有道理的,毕竟把一个神经元的计算打包成一条指令,是非常科学合理的专用加速器设计方案。
下图是中科院计算所团队成员作为第一作者与法国Inria、瑞士EPFL联合发表于国际计算机架构年会(ISCA2015)的ShiDianNao在图像处理中的应用,其中的红色格栅方块就是该芯片在系统中的位置。
图中可以看到,整个系统连接了两块图像传感器,传感器采集到的图像通过Camera Serial Interfaces(CSI)接口连接到Video pipeline处理单元,进行Bayer重建、白平衡、降噪、压缩等等图像处理。
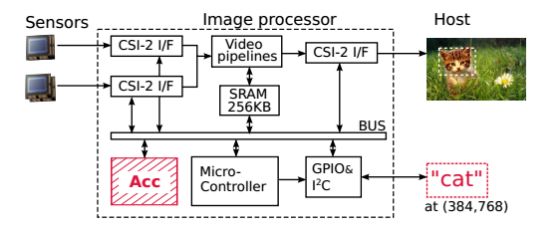
而ShiDianNao则在该系统中进行深度学习的模式识别,它内部实现了一个深度神经网络,经训练之后具有类似人类大脑一样的识别能力,可以从图像中识别出有一只猫,然后将识别出“猫”的信息通过GPIO/I2C接口输出给主机。整个系统用一款微处理器做控制,协调各个部件的运行。整个系统的数据存储,使用了256KB的SRAM,为了节省功耗,并提高性能,并没有使用DRAM。
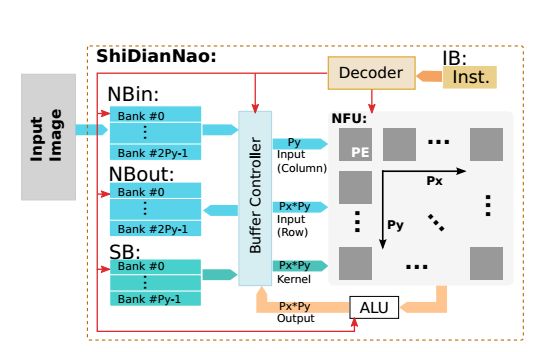
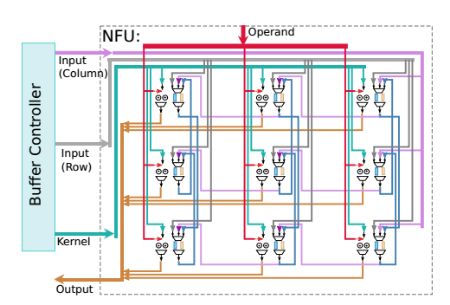
下图给出了ShiDianNao处理器的深度神经网络的架构。根据文献介绍,NBin是输入神经元的缓存,NBout是输出神经元的缓存,SB是突触的缓存。核心部件是NFU(neural functional unit)单元,它负责实现一个神经元的功能。ALU是数值运算单元,IB(decoder forinstructions)是指令译码器。
下图是ShiDianNao处理器的布局版图:

下图是神经元处理单元的核心部件NFU单元的结构。之前讲过,深度神经网络加速芯片的最大特点就是单指令可以完成多个神经元的计算。因此神经元计算单元的实现,就是这款加速芯片的核心。根据文献介绍,每个NFU又是一个阵列,包含一堆PE单元。每个NFU单元实现了16bit x 16bit的定点整数乘法,相比于浮点乘法,这会损失一部分运算精度,但是这种损失可以忽略不计。
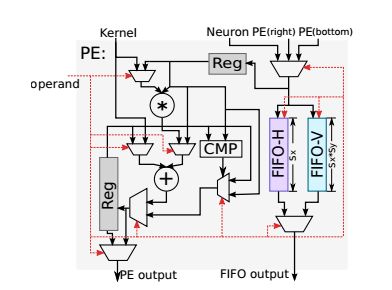
下图进一步给出了PE单元的结构,每个PE包含一个乘法器和一个加法器和比较器。可以单次完成乘累加运算或者累加运算或者一次比较运算。
由此,我们就自上而下的看完了整个ShiDianNao的架构设计。由于Google并没有公布TPU的设计,中科院和寒武纪公司亦没有公开商用的寒武纪芯片的具体架构,因此我们只能大概根据中科院前些年与法国和瑞士的合作者在学术界公开发表的ShiDianNao架构进行推断(我们假设寒武纪商用芯片和前些年的学术工作ShiDianNao在架构上有一脉相承之处,毕竟中科院计算所陈天石团队的成员都是主要架构师或论文的第一作者)。
【雷锋网注:DianNao系列架构和寒武纪在名称上已经有明确的界限。DianNao系列特指前期中科院计算所会同国际同行共同提出的处理器架构,是面向学术界的。从商业角度出发,寒武纪公司(中科院计算所下属企业)从未公开过寒武纪商用芯片的具体架构。】
根据ShiDianNao架构的论文描述,结合之前的论述,我们可以大致得出以下猜测:
(1)Google的TPU很有可能也是单指令完成多个神经元的计算。
(2)知道了Google的机器学习算法,就可以推断出TPU支持的指令集。
(3)根据Google对TPU的描述“能够降低运算精度”,猜测TPU内部可能也是采用更低位宽的定点或浮点乘法,虽然具体位宽未知。
(4)乘累加单元搭建的向量或矩阵指令仍然是基础运算的核心。
(5)Google强调TPU有领先7年的性能功耗比(十倍以上的提升),据此猜测,TPU可能也没有使用DRAM做存储,可能仍然使用SRAM来存储数据。但从性能功耗比提升量级上看,还远未达到专用处理器的提升上限,因此很可能本质上采用的是数据位宽更低的类GPU架构,可能还是具有较强的通用性。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker 长按识别二维码关注
长按识别二维码关注硬科技产业媒体
关注技术驱动创新
 人工智能谷歌
人工智能谷歌