人类知识多余?Deepmind新一代AlphaGo Zero自学3天打败AlphaGo
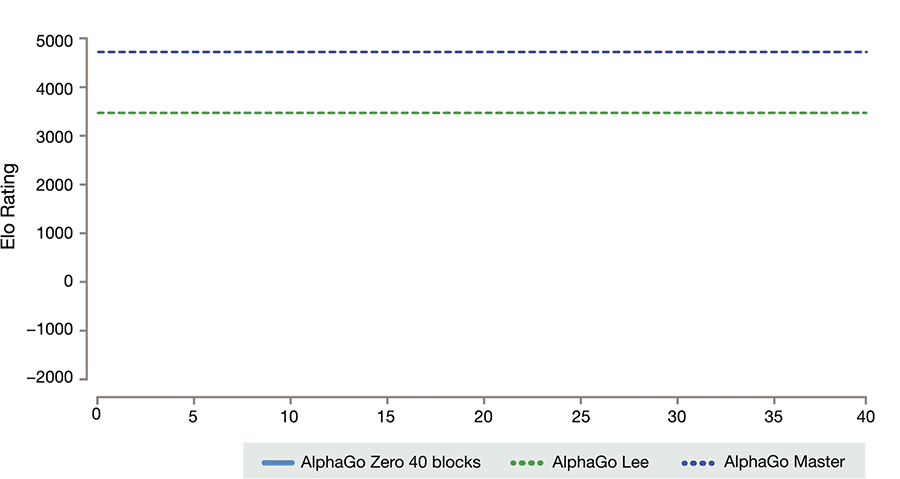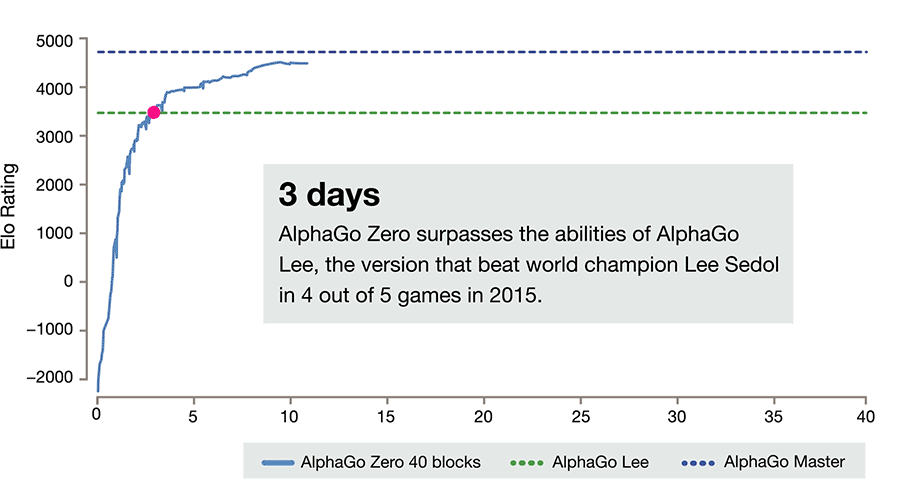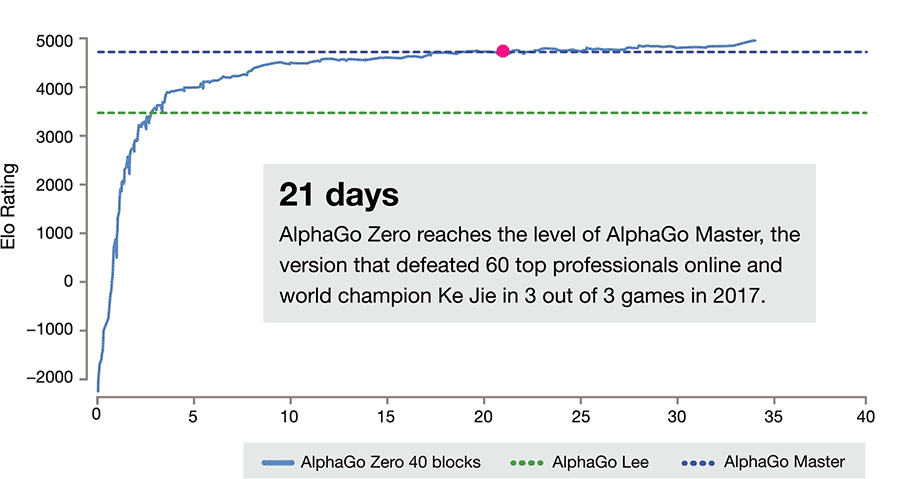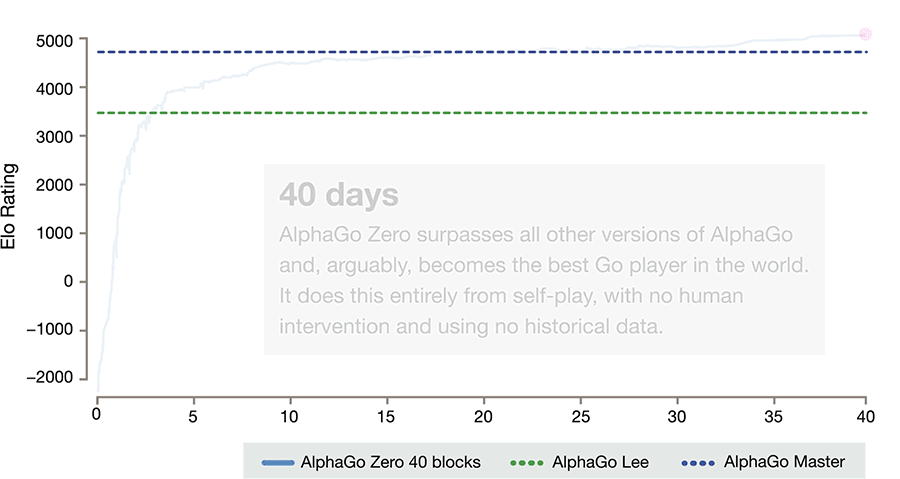
AlphaGo Zero3天时间就能达到击败李世石的AlphaGo Lee的水平,21天可以达到了之前击败柯洁的AlphaGo Master的水平。
今天凌晨,谷歌旗下Deepmind人工智能团队发布了一篇轰动AI界的论文,《Mastering the game of Go without human knowledge》(在没有人类知识的情况下掌握围棋),一句话总结这篇论文,他们研发的AlphaGo大表哥AlphaGo Zero能够在没有人类围棋对弈数据的情况下,直接通过自我纯强化学习,于短短的3天自我训练时间后,以100:0的战绩击败曾经的AlphaGo。

学霸中的战斗机,大表哥AlphaGo Zero完全靠“悟性”登上围棋巅峰
在下面的视频中,DeepMind研究人员简单的介绍了新一代的AlphaGo Zero的基本原理,
DeepMind联合创始人兼CEO Demis Hassabis表示:“AlphaGo Zero是我们项目中最强大的版本,它展示了我们在更少的计算能力,而且完全不使用人类数据的情况下可以取得如此大的进展。”
举个简单的例子,AlphaGo是经过大量的人工对弈数据学习和训练才一点点登上围棋的巅峰,它之所以能在去年打败李世石,并且在今年以Master的身份战胜排名世界第一的柯洁,都依赖于海量的人类对弈数据。
但是它的大表哥AlphaGo Zero是从一个完全不懂围棋知识和规则的神经网络开始,AlphaGo Zero每天就默默的自己一个人玩,不会像我们一样整天突击学习各种历史棋谱,参考前辈们的经验知识,它完全依靠自己的悟性(自我强化学习),在这个过程中,神经网络会不断更新、调整,来预测落子的位置,发展新的策略。
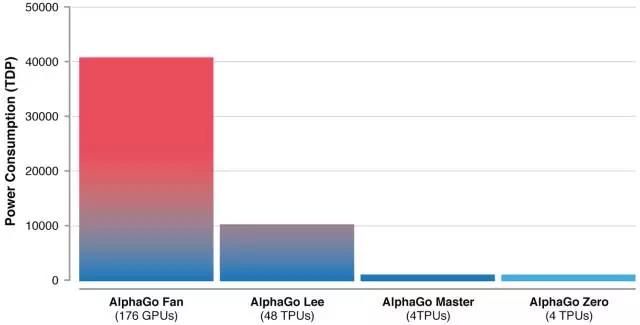
值得注意的是,AlphaGo Zero的自我训练强化时间更短,AlphaGo Zero只需要在4个TPU上花三天时间,自己左右互搏490万棋局。而它的大表弟AlphaGo需要在48个TPU上,花几个月的时间,学习三千万棋局,才能打败人类。对于AlphaGo Zero来说,3天时间就能达到了击败李世石的AlphaGo Lee的水平,21天可以达到了之前击败柯洁的AlphaGo Master的水平。
AlphaGo Zero给我们的启发
Deepmind的论文中也公布了AlphaGo Zero的一些技术细节,现在也有不少文章分享了相关的技术原理,镁客君简单的整理一下,其实主要在于AlphaGo Zero有更深的网络能更有效地直接从棋盘上提取特征。
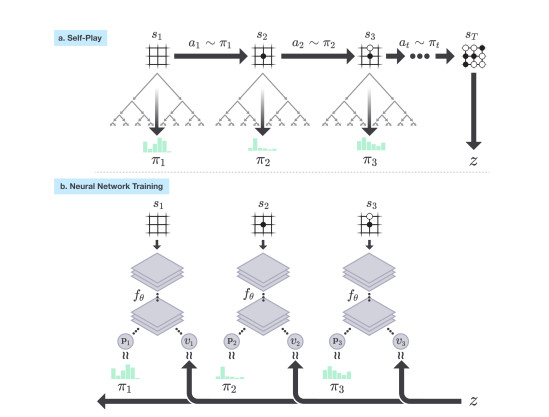
AlphaGo Zero在自我对弈中,在每一个落点s,神经网络fθ都会进行蒙特卡洛树(MCTS)搜索,得出每一步落子的概率π,再根据游戏规则计算出最终的获胜者z,这一过程可被视为一个强有力的评估策略操作。在这其中,神经网络参数不断更新,落子概率和价值 (p,v)= fθ(s)也越来越接近改善后的搜索概率和自我对弈胜者 (π, z),而新的参数也会被用于下一次的自我对弈来以增强搜索的结果。
更多的技术原理可以参考下面的论文:
https://deepmind.com/documents/119/agz_unformatted_nature.pdf
其实AlphaGo Zero之所以会一石激起千层浪,很大原因在于这种自我强化训练,不需要过多人工标注样本的自我强化训练未来可能的应用前景。
想象一下,以后可能再也不用花费大量的时间去为人工智能的应用或者产品做海量的数据准备工作,更何况很多情况下,数据的获取难度也非常之大。
尤其是很多小样本应用领域内,大量的人工标注几乎不可能实现,比如医疗数据方面,考虑到数据隐私性,以及各个医院之间的互通性,这些都让海量数据获取和训练难上加难。

而Demis Hassabis认为AlphaGo Zero的意义在于,“我们希望利用这样的算法突破来帮助解决现实世界的各种紧迫问题,例如蛋白质折叠或新材料设计。如果我们能在这些问题上取得与AlphaGo同样的进展,就有可能推动人类理解,并对我们的生活产生积极影响。”
AlphaGo Zero的技术理论是美好的,但是我们也需要思考的是,这种仅仅依靠神经网络算法来解决实际问题,其实际应用的范围到底有多大以及效果如何?
人工智能专家、美国北卡罗莱纳大学夏洛特分校洪韬教授表示,早期人工智能火了之后,被神经网络“解决”的实际问题寥寥无几;美国密歇根大学人工智能实验室主任Satinder Singh也表示,人工智能和人甚至动物相比,所知所能依然极端有限。
回顾AlphaGo成名史,聊聊AlphaGo Zero的下一步
出生于2014年的AlphaGo,2015年就击败了樊麾,成为第一个无需让子即可在19路棋盘上击败围棋职业棋手的电脑围棋程序。到了2016年3月,AlphaGo在和李世石的对战中一举成名,4:1的胜绩让它成为有史以来第一位非人类的名誉职业九段;之后升级版AlphaGo以“Master”的称号,挑战了中韩日台的一流高手,最终60战全胜;2017年,AlphaGo在浙江乌镇,和我国围棋选手柯洁进行对战,最终以打败柯洁成为世界第一正式退役谢幕。
那么对于AlphaGo Zero,大家也非常期待它会以什么样的身份正式亮相,镁客君觉得可能会是这样的情景:
今年8月的时候,DeepMind 曾公开宣布,星际争霸 2 将会是其下一个目标。自学能力如此强的AlphaGo Zero极有可能会在星际争霸AI中亮相。

和围棋对弈相比,星际争霸 AI 也是基于开发者人工编写的规则和策略,此前的对战中,AI会观看海量的比赛数据,然后尝试各种不同的策略,在反复的训练和学习后,从其中选出最有可能获胜的一种。可以想象,按照AlphaGo Zero的自我强化学习能力,它完全能够在自我博弈过程中去寻找到最佳的策略。
最后,在看到柯洁发的这条微博动态后,
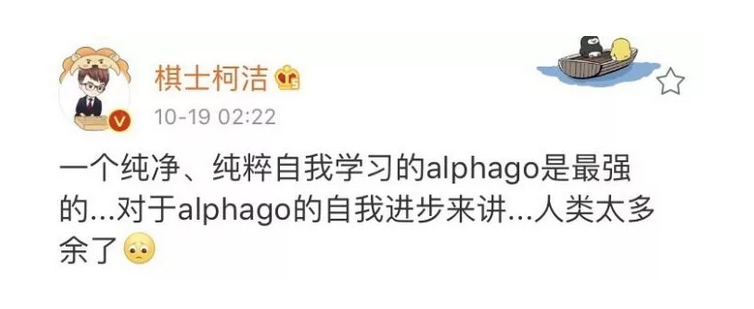
一声唏嘘,在这样的人工智能面前,人类的学习经验价值似乎越来越低,人类会太多余吗……
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker 长按识别二维码关注
长按识别二维码关注硬科技产业媒体
关注技术驱动创新
 Deepmind人工智能机器学习
Deepmind人工智能机器学习