HBM内存,也要搞“集成显卡”
这不仅将推动超大规模AI模型的普及,更可能催生新的算法优化方向。

在AI加速渗透各行业的背景下,芯片架构设计也随着需求开始不断变革。
据韩媒ETNews报道,英伟达已着手计划将部分GPU功能集成到基础裸片中,这种“嵌入式GPU”的构想类似我们常见的集成显卡,但封装从CPU变成了内存。如果一切顺利,这一技术路线很有可能成为突破当前AI算力瓶颈的关键突破口。
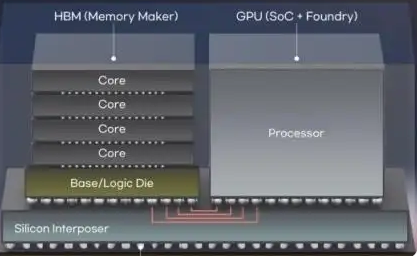
当前HBM技术采用“多层DRAM堆叠+基底”的经典架构,基底主要承担输入输出功能。而“嵌入式GPU”方案则通过在HBM基底裸片中集成GPU核心单元,实现计算与存储的物理层融合。这种设计显著缩短了数据传输路径,理论上可将AI系统效率提升30%以上。
韩国科学技术院电气工程系金正浩教授指出:“存储芯片与计算芯片的界限正在消失,这是半导体技术发展的必然趋势。”
报道称,英伟达计划在2024年量产的HBM4基础上开发定制化基础裸片,并将其纳入新一代Vera Rubin超级芯片的设计框架。该芯片通过两颗大尺寸算力芯片与八组HBM4堆栈的协同,实现了单颗GPU 288GB、整板576GB的HBM4内存容量。
不只是英伟达,AMD也在同步推进技术迭代,其最新发布的Instinct MI430X加速卡搭载CDNA架构,支持432GB HBM4内存及19.6TB/s带宽,有望成为AI算力领域的又一里程碑。
当然,“嵌入式GPU”架构目前来说仍面临多重技术挑战。
首先是物理空间的制约,受限于TSV(硅通孔)堆叠结构,可用于集成GPU核心的裸片面积十分有限;其次是电源分配难题,高功耗的GPU单元如何在紧凑空间内实现稳定供电;最后是散热问题,高密度集成下内层芯片的热管理成为关键。某芯片设计公司资深工程师表示:“这些挑战需要封装工艺、材料科学和芯片设计的协同突破,但并非不可逾越。”
为了推动新技术的更新,存储厂商也需要发力。SK海力士与三星已率先行动,前者投资10亿美元扩建HBM生产线,后者则在2023年推出HBM3E产品为HBM4E定制化铺路。行业观察家指出:“具备先进封装与逻辑芯片能力的企业将在竞争中占据先机,而仅专注于存储模组的传统厂商将面临转型压力。”
从技术演进角度看,2026年将成为AI芯片发展的重要分水岭。随着HBM4E向定制化方向演进,存储芯片与计算单元的融合将加速推进。韩国科学技术院的测算显示,“存内计算”架构有望使AI训练效率提升2-3倍,同时降低40%以上的能耗。这不仅将推动超大规模AI模型的普及,更可能催生新的算法优化方向。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker 长按识别二维码关注
长按识别二维码关注硬科技产业媒体
关注技术驱动创新
 存储嵌入式技术投资韩国
存储嵌入式技术投资韩国