AI芯片“最强辅助”HBM,发展到哪一步?| 研报推荐
混合键合与TSV是3D封装的核心,HBM“连接”与“堆叠”带来设备材料端发展新机遇。

注:原文为华金证券《HBM迭代,3D混合键合成设备材料发力点》,分析师:孙远峰、王海维
随着英伟达的市值冲破2万亿美元,英伟达的股票一夜间成了世界上最值钱的商品。
而这还远不是英伟达市值的极限,靠着向全世界售卖高性能GPU,英伟达的垄断地位仍会持续下去。
但另一方面,高性能GPU供不应求的情况始终得不到好转,其背后原因之一——存储大厂的HBM(高带宽内存)显存产能提不上来,严重影响了英伟达的产能。
HBM显存并不是什么新鲜事物,对比消费线常见的GDDR显存,前者价格相当昂贵,基本只在高密度计算集群中使用。
不过随着AI芯片需求不断增加,存储巨头开始全力冲刺HBM技术,HBM显存的性能与使用场景都有显著提升。
目前拥有第五代HBM3E技术的SK海力士已经拉满了2024年的产能,同为存储大厂的三星与美光同样全力为英伟达供货。
那么作为AI芯片“最强辅助”的HBM,究竟强在哪里?
在华金证券推出的半导体行业深度报告《HBM迭代,3D混合键合成设备材料发力点》里,分析师从“设备材料”的角度深度分析了HBM的最新情况。
以下为研报内容精选:
什么是HBM?
·CPU与存储之间,存在着“内存墙”
随着摩尔定律的不断迭代,CPU运行速度快速提升,目前CPU主频高达5GHz,而DRAM内存性能取决于电容充放电速度以及DRAM与CPU之间的接口带宽,存储性能提升远慢于CPU,DRAM内存带宽成为制约计算机性能发展的重要瓶颈;
一般来说,DDR4内存主频为2666~3200MHz,带宽为6.4GB/s,但是在AI应用中(高性能计算/数据中心),算力芯片的数据吞吐量峰值在TB/s级,主流的DRAM内存或显存带宽一般为几GB/s到几十GB/s量级,与算力芯片存在显著的差距, “内存墙”由此形成。
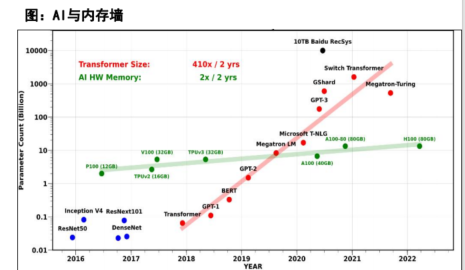
以Transformer类模型为例,模型大小平均每两年翻410倍,而AI硬件上的内存大小仅仅是以每年翻2倍的速率在增长;
此外,内存墙问题不仅与内存容量大小有关,也包括内存的传输带宽——目前的内存容量和传输的速度都大大落后于硬件的计算能力。
一般来说,传统DRAM需要大量空间与CPU/GPU等处理器通信,同时封装的形式看需要通过引线键合或PCB进行连接,因此DRAM不可能对海量数据进行并行处理。
·HBM概念
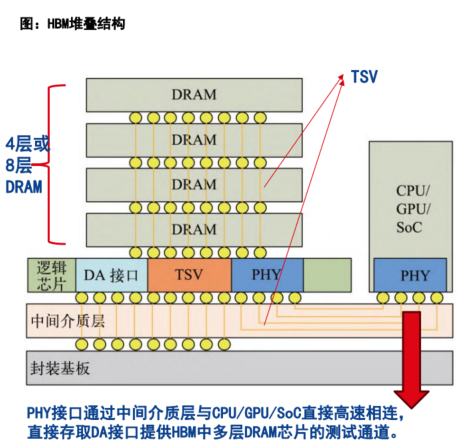
随着2.5D/3D系统级封装(SiP)和硅通孔(TSV)技术日益 成熟,为高带宽、大容量的存储器产品提供基础;
而高带宽存储器HBM(Highband Memory),使用硅通孔TSV和微凸块技术垂直堆叠多个DRAM,因此可以显著提升数据处理速度,同时性能提升的同时尺寸有所减少;
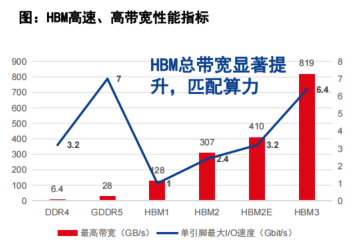
从2013年开始,JEDEC制定了高带宽存储器系列标准(包括 HBM,HBM2,HBM2E,HBM3),其中,HBM3相比2代标准有显著提升,芯片单个引脚速率达到6.4Gbit/s,总带宽超过1TB/S。
·HBM特点
HBM2E和HBM3的单引脚最大输入/输出(I/O)速度分别达3.2Gbit/s和6.4Gbit/s,低于GDDR5存储器的7Gbit/s,但HBM的堆栈方式可通过更多的I/O数量使总带宽远高于GDDR5;例如HBM2带宽可以达到307 GB/s;
海力士官网数据显示:HBM3E的数据处理速度,相当于可以在1s内下载230部全高清(FHD)级电影(每部5千兆字节,5GB),优化后可用于处理人工智能领域的海量数据。
同时,由于采用微凸块和TSV技术,存储和算力芯片信号传输 路径短,单引脚I/O速率较低,使HBM具备更好的内存功耗能效特性;
以DDR3存储器单引脚I/O带宽功耗为基准,HBM2的I/O功耗比明显低于DDR3/DDR4和GDDR5,相比于 GDDR5存储器,HBM2的单引脚I/O带宽功耗比数值降低42%。
总体来说,HBM的技术特点:1、高速;2、高带宽;3、更低功耗。

同时,HBM又具备可扩展容量的结构特点。具体如图:
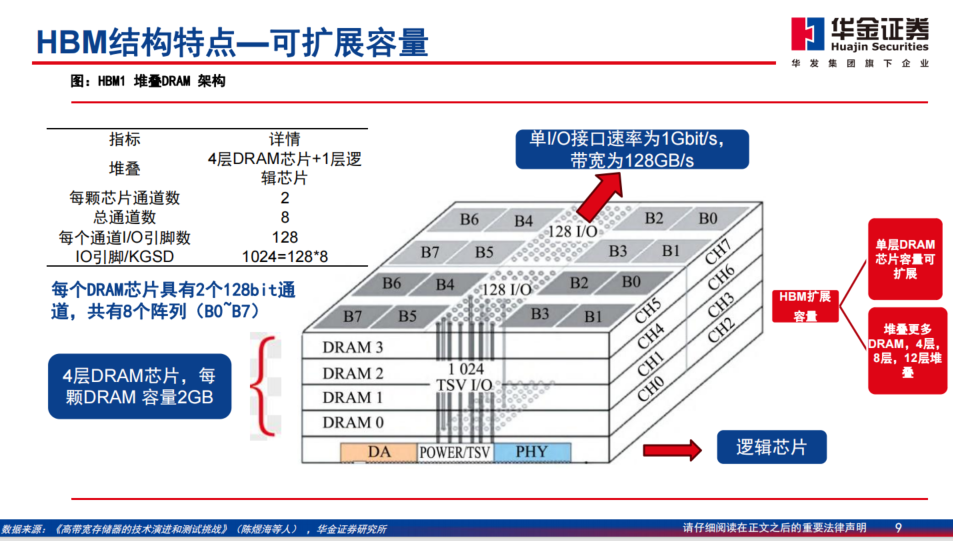

AI算力快速迭代,HBM为最强辅助
随着美国商务部工业与安全局 (BIS)针对高算力芯片管控指标不断升级,增加了先进计算最终用途管控,AI算力的高需求带动HBM成最强“辅助”,主要体现在HBM的供给侧趋势。
1、从三大家HBM供给侧趋势看,HBM3及以上版本逐渐成为主流,从容看24GB/32GB逐渐替代16GB成为主流配置;
2、HBM4预计于2026年开始量产;
3、工艺节点看,HBM3e 三星和海力士的制程节点为1 alpha,美光为 1 beta;
4、海力士与三星占据主要市场份额;
5、假设2023年和2024年HBM单价分别为15美元/12美元,2024年HBM市场规模预计为120亿美元。
此外,英伟达、谷歌、AMD、AWS等科技巨头的HBM使用量有明显上升。
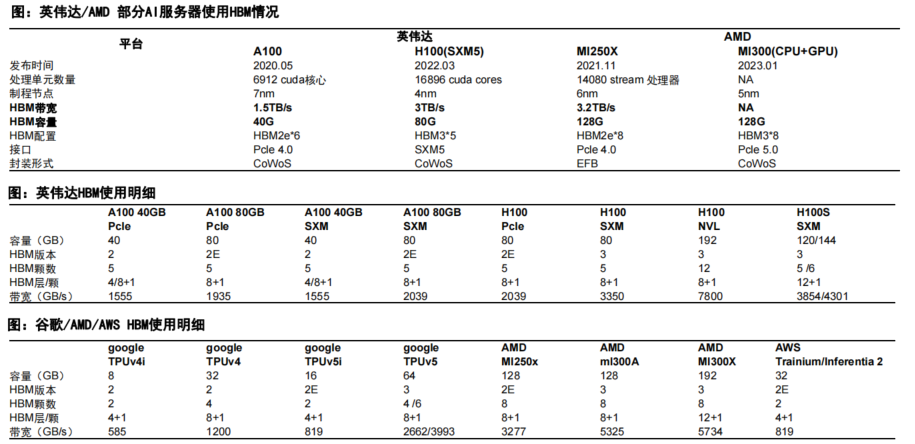

“连接”与“堆叠” ,3D混合键合成HBM新趋势
HBM制造的核心,包括TSV和封装,垂直堆叠等技术。
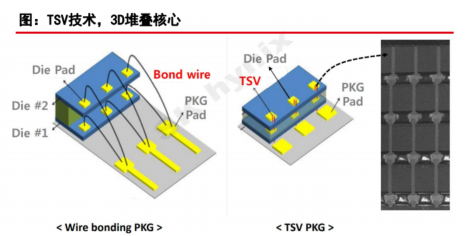
根据《半导体工艺与设备 》介绍,TSV不采用传统的布线方法来连接芯片与芯片,而是通过在芯片上钻孔并填充金属等导电材料以容纳电极来垂直连接芯片。
在制作带有TSV的晶圆后,通过封装在其顶部和底部形成微凸块,然后连接这些凸块。由于 TSV 允许凸块垂直连接,因此可以实现多芯片堆叠。
目前HBM的堆叠技术包括MR-MUF以及TC-NCF等;
其中,MR-MUF(向上堆叠方式,Mass Reflow – Molded Underfill),是指将半导体芯片堆叠后,为了保护芯片和芯片之间的电路,在其空间中注入液体形态的保护材料,并固化的封装工艺技术。
与每堆叠一个芯片铺上薄膜型材料的方式对比,工艺效率高,散热方面也更有效;
具体步骤:
1、连接芯片的微凸块采用金属塑封材料;
2、一次性融化所有的微凸块,连接芯片与电路;3)芯片与芯片之间或者芯片与载板之间的间隙填充,绝缘和塑封同时完成。
而TC-NCF(Thermo Compression – Non-Conductive Film,非导电薄膜),是一种在芯片之间使用薄膜进行堆叠的方法,与MR-MUF相比,该互连技术导热率较低;速度较慢;
此前,SK 海力士在HBM2e中使用 TC-NCF。
而到了HBM4时代后,海力士正在加速开发新工艺“混合键合”(Hybrid Bonding ),并将成为未来新趋势。
截止目前, HBM的DRAM芯片之间通过“微凸块”材料进行连接,通过混合键合,芯片可以在没有凸块的情况下连接,从而显著减小芯片的厚度;
当间距小到20um以内,热压键合过程中细微倾斜使得钎料变形挤出而发生桥连短路,难以进一步缩减互联间距;
HBM芯片标准厚度为720um,预计2026年左右量产的第六代HBM4需要纵向垂直堆叠16层DRAM芯片,当前的封装技术很难让客户满意,所以混合键合的应用被认为是必然的趋势;
2023年海力士用于第三代HBM产品(HBM2e)测试混合键合技术,规格低于HBM4产品;
同时海力士拟计划将新一代的HBM与逻辑芯片堆叠在一起,取消硅中介层。
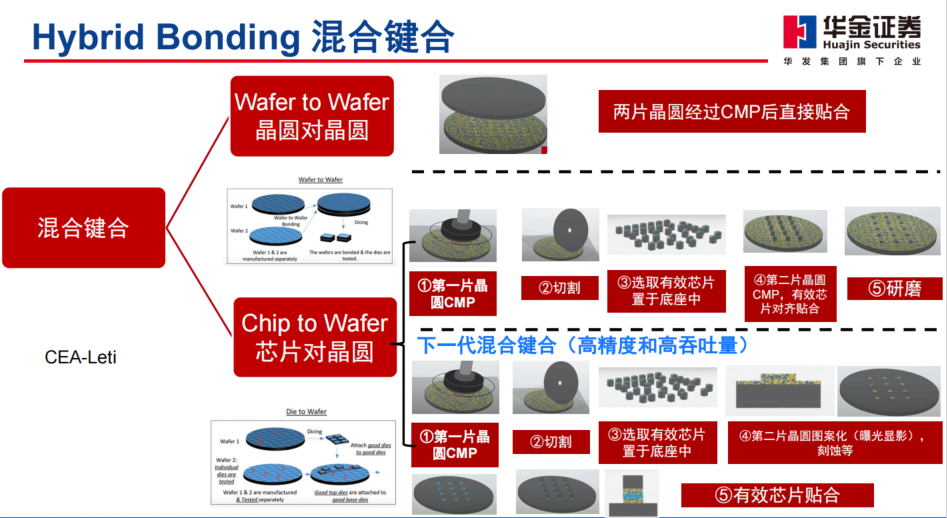
·混合键合定义:
1、混合键合是一种永久键合,将介电键合(SiOx)与嵌入式金属(Cu)结合起来互联,形成电介质和金属-金属键;
2、使用紧密嵌入电介质中的微小铜焊盘可以提供比铜微凸块多1000倍的I/O连接。支持3D封装和先进的存储立方体更高的互连密度;
3、混合键合可以实现低于10um的键合间距,当接近10um尺寸时,带有焊锡尖端的铜凸块会遇到可靠性问题,从而导致转向混合键合。
按照分类,混合键合又可以分类成:
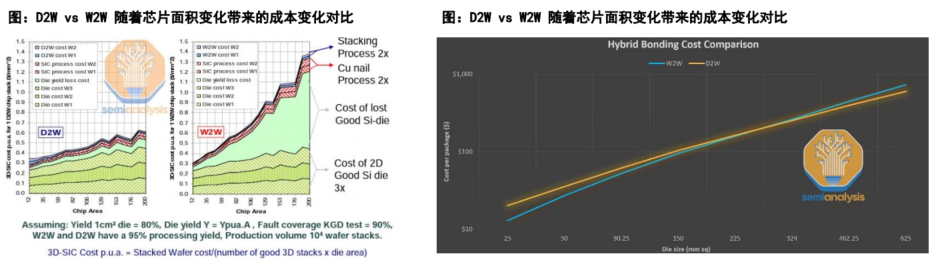
1、晶圆到晶圆(Wafer-to-Wafer):两个制造好的晶圆直接键合在一起,W2W提供更高的对准精度、吞吐量和键合良率,目前绝大多数混合键合通过W2W完成,比较典型的是长江存储3D NAND Xstacking技术的突破;
2、芯片到晶圆(Die-to-Wafer):将切割好的Die贴到另
一个完成的晶圆上,与晶圆上的Die实现键合,可以分为两类:
可以按顺序一颗一颗放置到另一片产品晶圆的对应位置上,位置精度会提高;将切割好的Die用临时键合的方式粘贴到Carrier晶圆上,整个晶圆与另一片晶圆键合再解键合,类似传统的W2W。
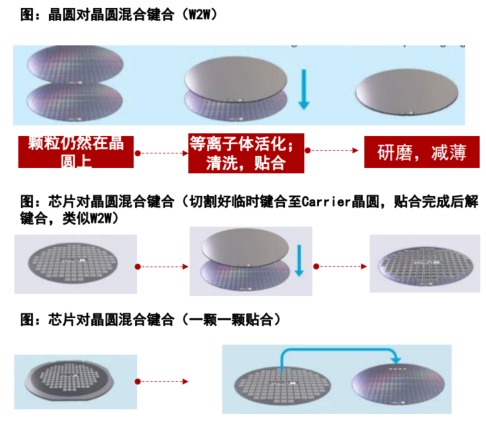
两者进行相比:
W2W键合是相对成熟的工艺,也不是特别昂贵,目前,W2W键合可以实现50nm以下的对准精度,W2W存在的主要问题是无法选择已经良好的芯片(KGD)进行封装,会导致将有缺陷的芯片贴合至优质芯片,从而导致优质芯片的损失,所以W2W一般应用于良率非常高的晶圆;
而D2W方式可以应用良率相对较差但仍然具备商业价值的产品,D2W在键合方面更具挑战性,因为每个晶圆都需要更多的键合步骤,会引入颗粒污染。
(更多内容请参考研报原文)
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker 长按识别二维码关注
长按识别二维码关注硬科技产业媒体
关注技术驱动创新
 AI技术摩尔定律硬件英伟达
AI技术摩尔定律硬件英伟达